Viele Unternehmen investieren beträchtliche Summen in leistungsfähige ETL-Tools – und kämpfen dennoch mit komplexen Deployments, schwer wartbarem Code und eingeschränkter Transparenz. Die Wahl der richtigen Integrationsarchitektur ist heute weniger eine Tool-Entscheidung als eine strategische Weichenstellung. Während klassische ETL-Plattformen auf visuelle Modellierung und proprietäre Laufzeitumgebungen setzen, verfolgen Low-Code- und deklarative Pipeline-Ansätze ein anderes Paradigma: Infrastruktur als Code, Transformation als deklarative Logik und Deployment als automatisierter Prozess.
Low-Code Pipelines mit Dynamic Tables in Snowflake

Aufgabenstellung
Situation / Herausforderung
Mit Dynamic Tables unterstützt Snowflake einen deklarativen Ansatz für Datenpipelines. Anstatt komplexe ETL-Jobs mit expliziter Orchestrierung zu definieren, beschreibt man lediglich den gewünschten Zielzustand in Form einer SQL-Definition. Snowflake übernimmt automatisch die inkrementelle Aktualisierung, Abhängigkeitsauflösung und Ausführung im Hintergrund. Dadurch reduziert sich der operative Aufwand erheblich: Entwickler konzentrieren sich auf die Transformationslogik, während Scheduling, Change-Tracking und Performance-Optimierung von der Plattform gesteuert werden. Dynamic Tables ermöglichen somit wartbare, transparente und cloud-native Datenpipelines ohne klassische ETL-Tool-Komplexität.
Zusätzlich stellt Snowflake eine visuelle Oberfläche bereit, mit der sich der Lade- und Refresh-Prozess der Dynamic Tables überwachen und steuern lässt. Über diese Ansicht können Abhängigkeiten zwischen Tabellen nachvollzogen, Verarbeitungsstatus eingesehen und potenzielle Fehlerquellen schnell identifiziert werden. Zudem bietet sie Transparenz über Kennzahlen wie die Anzahl verarbeiteter Datensätze pro Tabelle oder die Dauer einzelner Refresh-Zyklen. Dadurch wird der deklarative Ansatz um eine komfortable Monitoring- und Kontrollmöglichkeit ergänzt.
Vorgehensweise
Vorgehensweise und Kundennutzen
 Leistung sumIT
Leistung sumIT
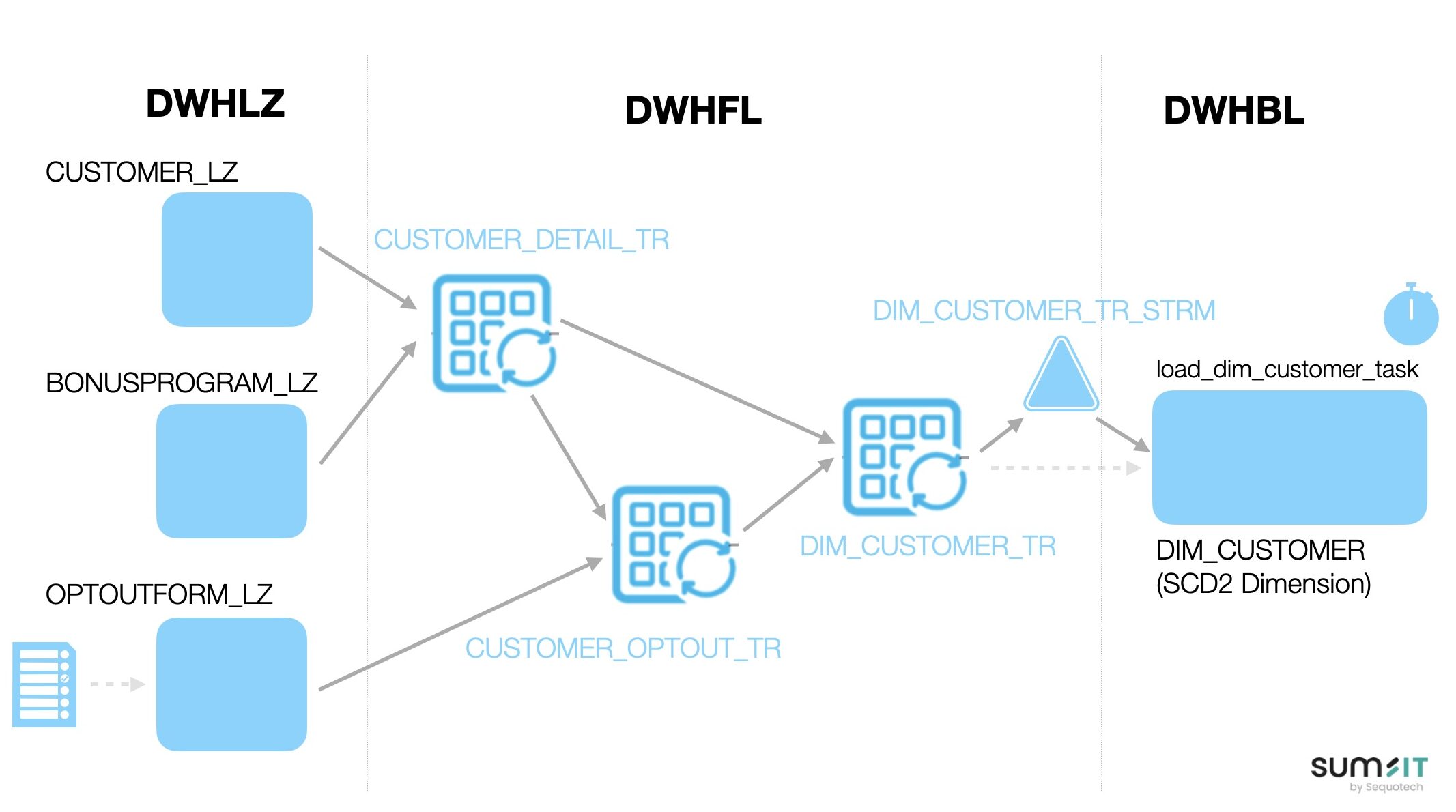
Ein wichtiger Use Case für Dynamic Tables wäre z.B. das regelmässige Laden einer SCD-2-Dimension in Near Real Time innerhalb eines Data Lakehouse mit Medallion-Architektur.
Im Bronze Layer (oder Landing Zone) werden die Daten 1:1 aus den Quellsystemen übernommen. Im Silver Layer (oder Foundation Layer) werden die Daten aus unterschiedlichen Quellen integriert und transformiert. Im Gold Layer (oder Business Layer) befindet sich schliesslich die SCD-2-Dimension, also eine Dimension, in der jede Änderung mit einem gültigen Zeitraum (VALID_FROM und VALID_TO) versioniert wird.
Hierfür wird ein Stream auf der entsprechenden Transformations-Dynamic Table definiert. Sobald neue oder geänderte Datensätze zur Verarbeitung bereitstehen, wird eine Task ausgelöst, welche die Erstellung bzw. Aktualisierung der entsprechenden Versionen in der Zieldimension vornimmt. Damit erfolgt die Aktualisierung deklarativ und vollautomatisch – ohne komplexe Scheduling-Logik oder menschliches Eingreifen.
Leistung sumIT
sumIT ist Ihr Partner für moderne Datenarchitekturen in Snowflake. Wir helfen Ihnen, die Struktur und Eigenheiten Ihrer Quelldaten fundiert zu verstehen, eine skalierbare Medallion-Architektur zu modellieren und Speicher- sowie Compute-Ressourcen optimal zu nutzen. Gemeinsam definieren wir deklarative Datenpipelines und implementieren die erforderlichen Komponenten – von Streams und Tasks bis hin zu performanten SQL-Transformationen – damit Ihre Daten zuverlässig, effizient und bedarfsgerecht bereitgestellt werden.
Tools und Technologie
- Snowflake Datenplatform
- Dynamic Tables
- Streams
- Tasks
- Pipeline DAG
- Snowsight